Football Automute
Project Status: 60%
I’ve gotten pretty sick of American football’s non-stop commercials, to the point where I reprogrammed one of my mouse buttons to be mute adn still just end up leaving the game on mute. Well, as pleasent as music is to listen, sometimes I want to hear the commentary in the background so I decided to fight back. Why not build a machine learning algorithm to automatically mute the game for me…
The Data
I used kazam to screen capture an NFL game and several advertisements, then parsed the audio into around a hundred 5 second clips using ffmpeg. I captured the video because it might prove useful eventually, especialy since an external device wouldn’t be able to unmute automatically without an audio feed. I also chose 5 seconds as an interval because it seemed reasonable to allow the learner enough time to properly evaluate whether the audio is indeed a commercial.
The Code
The code is pretty straight forward and borrows heavily from Mike Smales excellent resource on Medium for audio classification. His plan to obtain the Mel Frequency Cepstrum Coefficients for the audio and feed the spectogram image into a convolutional nueral network is nothing short of brilliant.
The code is written in python and uses keras as a tensorflow wrapper, numpy, pandas, and sklearn for data management/manipulation as well as librosa, a wav audio library.
import os
import librosa
import librosa.display
import struct
import pandas as pd
import numpy as np
from datetime import datetime
from sklearn import metrics
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from tensorflow.python.keras import backend
from keras.utils import to_categorical
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Convolution2D, Conv2D, MaxPooling2D, GlobalAveragePooling2D
from keras.optimizers import Adam
from keras.callbacks import ModelCheckpoint
# get basic file properties to make sure files are comparable
def readFileProperties(filename):
waveFile = open(filename, "rb")
fmt = waveFile.read(36)
numChannels = struct.unpack('<H', fmt[10:12])[0]
sampleRate = struct.unpack('<I', fmt[12:16])[0]
bitDepth = struct.unpack('<H', fmt[22:24])[0]
waveFile.close()
return (numChannels, sampleRate, bitDepth)
# get descriptive audio data coefficients for nueral network to process
def extractFeatures(filename):
try:
audio, sampleRate = librosa.load(filename, res_type='kaiser_fast')
mfccs = librosa.feature.mfcc(y=audio, sr=sampleRate, n_mfcc=40)
except Exception as e:
print(e)
return None
mfccs = mfccs[:, :215] # limit clips to ~5 seconds
return mfccs
# view mel frequency cepstrum coefficient spectogram
def viewMfcss(mfccs, title):
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 4))
librosa.display.specshow(mfccs, x_axis='time')
plt.colorbar()
plt.title(title)
plt.tight_layout()
plt.show()
# parse audio data into a pandas dataframe
audiodata = []
for i in range(106):
filename = "wav-audio/nfl-%03d.wav" % i
metadata = readFileProperties(filename)
features = extractFeatures(filename)
# if i == 1:
# viewMfcss(features, "NFL MFCCS")
audiodata.append([0, metadata[0], metadata[1], metadata[2], features])
for i in range(19):
filename = "wav-audio/ad2-%03d.wav" % i
metadata = readFileProperties(filename)
features = extractFeatures(filename)
# if i == 1:
# viewMfcss(features, "AD MFCCS")
audiodata.append([1, metadata[0], metadata[1], metadata[2], features])
dataFrame = pd.DataFrame(audiodata, columns=['adBool', 'numChannels', 'sampleRate', 'bitDepth', 'features'])
print("\nDATAFRAME")
print(dataFrame)
print()
# convert data to proper shape/form for nueral network
x = np.array(dataFrame.features.tolist())
y = np.array(dataFrame.adBool.tolist())
# print("x shapes is " + str(x.shape))
# print("y shapes is " + str(y.shape))
le = LabelEncoder()
y = to_categorical(le.fit_transform(y))
# split data in 80/20 into training and testing sample
xTrain, xTest, yTrain, yTest = train_test_split(x, y, test_size=0.2, random_state=42)
# print(xTrain.shape)
# print(yTrain.shape)
# print(xTest.shape)
# print(yTest.shape)
numRows = 40
numCols = 215
numChans = 1
xTrain = xTrain.reshape(xTrain.shape[0], numRows, numCols, numChans)
xTest = xTest.reshape(xTest.shape[0], numRows, numCols, numChans)
# Construct model
model = Sequential()
model.add(Conv2D(16, (2,2), input_shape=(numRows, numCols, numChans), activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.2))
model.add(Conv2D(32, (2,2), activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.2))
model.add(Conv2D(64, (2,2), activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.2))
model.add(Conv2D(128, (2,2), activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.2))
model.add(GlobalAveragePooling2D())
numLabels = y.shape[1]
model.add(Dense(numLabels, activation='softmax'))
model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer='adam')
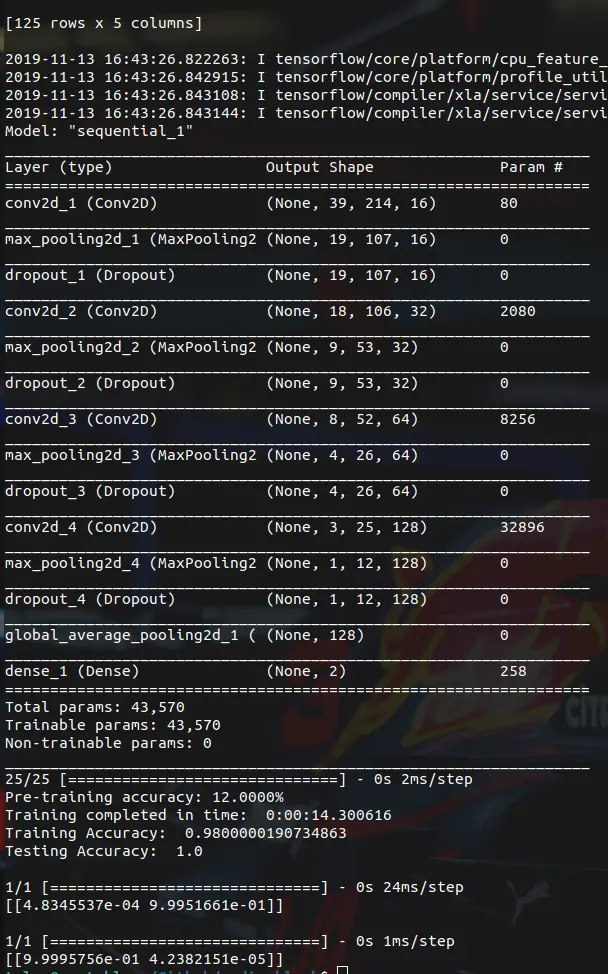
model.summary()
# Calculate pre-training accuracy
score = model.evaluate(xTest, yTest, verbose=1)
accuracy = 100 * score[1]
print("Pre-training accuracy: %.4f%%" % accuracy)
# Train the model
start = datetime.now()
model.fit(xTrain, yTrain, batch_size=256, epochs=100, validation_data=(xTest, yTest), verbose=0, use_multiprocessing=True)
duration = datetime.now() - start
print("Training completed in time: ", duration)
# Evaluating the model on the training and testing set
score = model.evaluate(xTrain, yTrain, verbose=0)
print("Training Accuracy: ", score[1])
score = model.evaluate(xTest, yTest, verbose=0)
print("Testing Accuracy: ", score[1])
# Use the model to predict
print()
testX = extractFeatures("originals/ad1.wav")
testX = testX.reshape(1, numRows, numCols, numChans)
print(model.predict(testX, batch_size=None, verbose=1, steps=None))
print()
testX = extractFeatures("originals/nfl.wav")
testX = testX.reshape(1, numRows, numCols, numChans)
print(model.predict(testX, batch_size=None, verbose=1, steps=None))
Output, showing above 95% accuracy
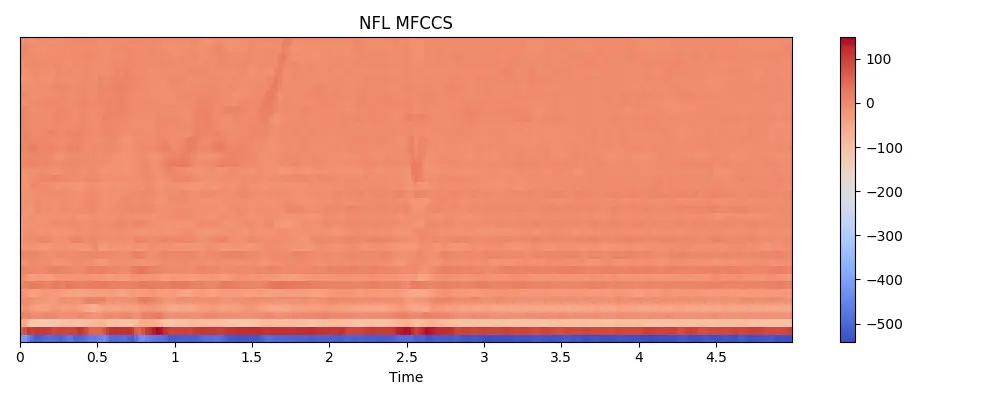
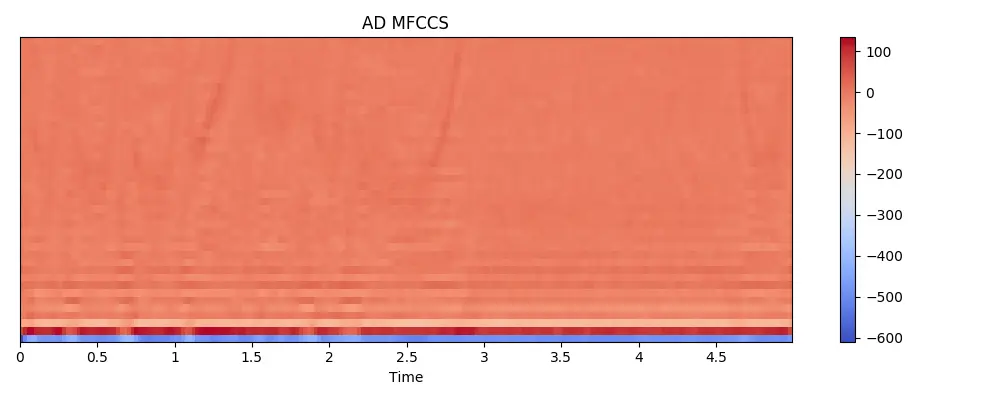
Next steps
Off to a good start with the classification being so accurate. Next step is to implement mute and unmute on an permanent audio thread to the python script.
Eventually I would like to connect a low cost HDMI board to any TV but I’m not quite sure how the mute functionality would work with regards to maintaining an audio input stream.